TinyLLMA Framework for Training and Deploying Language Models at the Edge |
Version | v0.1 | |
|---|---|---|---|
| Updated | |||
| Author | Savitha
Viswanadh Kandala Pramuka Medaranga Ambuj Varshney |
License | Apache-2.0 |
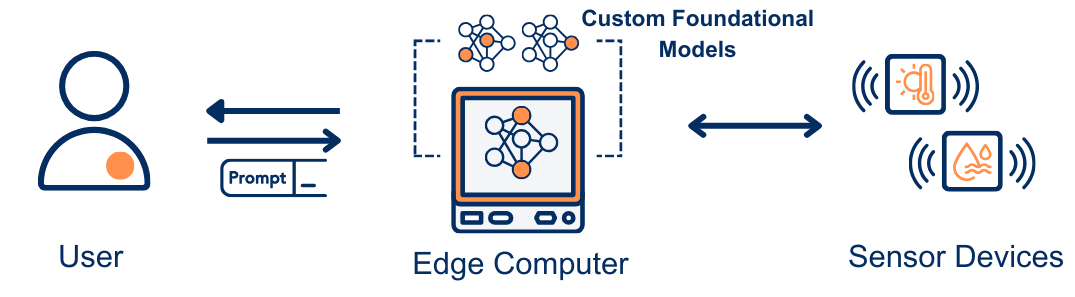
Language models exhibit numerous capabilities that are suitable for embedded sensing. As an example, to interact with the end-users, analyse sensor informnation. However, their large parameter sizes impose significant memory and processing requirements for inference. This makes on-device inference challenging for mobile and edge platforms, often necessitating remotely hosted models accessed via network calls. Remote inference, in turn, introduces challenges such as latency, unreliable network connectivity, and also privacy concerns with sharing sensitive sensor data with third-party.
We hypothesize that when trained with carefully curated datasets and fine-tuned appropriately, language models (30–120M parameters) achieve comparable accuracy to larger models while remaining feasible for deployment on the most resource-constrained edge platforms. To this end, we present a framework that enables training such foundational models, offering both high token generation rates and accuracy. Furthermore, the framework simplifies the deployment of these tiny language models at the edge.
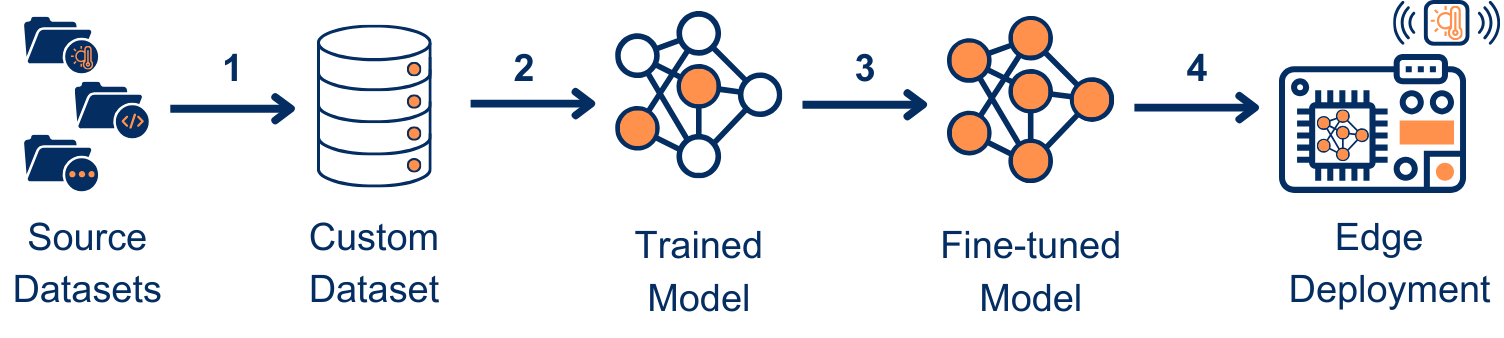
TinyLLM offers the following functionality to the end-users:
1.Dataset Preparation: Users can prepare their own sensing datasets for model pre-training. The framework provides tools to preprocess the data and convert it into a format suitable for pre-training.
2.Pre-Training: Users can train custom language models using their own datasets. The framework builds upon the architecture of GPT-2 foundational models with varying parameter sizes (30M, 51M, 82M, 101M, and 124M) as a starting point for training custom models.
3.Fine-Tuning: Users can fine-tune custom or off-the-shelf pre-trained models with domain-specific data for downstream embedded sensing tasks.
4.Deployment: Users can deploy trained models on even the most constrained edge devices, such as SBCs like Raspberry Pi and Orange Pi. The framework includes provisions to convert trained models into formats optimized for edge device deployment.
TinyLLM has been used to train and fine-tune small custom models for two downstream tasks: Hand Gesture Recognition and Robot Localization using in-house datasets. The accuracy of these models was compared to that of popular off-the-shelf models:
| Model | # Parameters (Billion) | Model Size (GiB) | Accuracy (%) |
|---|---|---|---|
| Tiny Model | 0.10 | 0.277 | 98.44 |
| Tiny Model | 0.12 | 0.329 | 93.02 |
| Microsoft Phi 3 | 3.82 | 7.2 | 100 |
| Meta Llama 3 | 8.03 | 15 | 93 |
| Model | # Parameters (Billion) | Model Size (GiB) | Accuracy (%) |
|---|---|---|---|
| Tiny Model | 0.08 | 0.231 | 98.57 |
| Tiny Model | 0.12 | 0.329 | 100 |
| Microsoft Phi 3 | 3.82 | 7.2 | 100 |
| Meta Llama 3 | 8.03 | 15 | 100 |
The results demonstrate that the custom models trained using TinyLLM either outperform or perform on par with the off-the-shelf models in terms of accuracy. Furthermore, these custom models are significantly smaller in size, making them ideal for deployment on edge devices.
Note: These models were pre-trained on a mix of general IoT sensor data before being fine-tuned for specific downstream tasks.
Follow the instructions provided in the GitHub repository.
Pre-trained models trained on mix of sensor and web data, are available for download on our Hugging Face page.
1.Savitha Viswanadh Kandala, Pramuka Medaranga, Ambuj Varshney. 2024. Technical Report. TinyLLM: A Framework for Training and Deploying Language Models at the Edge Computers
1.Savitha Viswanadh Kandala and Ambuj Varshney. 2024. Your Data, Your Model: A Framework for Training and Deploying Foundational Language Models for Embedded Devices In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking (ACM MobiCom ’24). Association for Computing Machinery, New York, NY, USA, 1704–1706. https://doi.org/10.1145/3636534.3697466
1.Savitha Viswanadh Kandala and Ambuj Varshney. 2024. A Framework for Training and Deploying Foundational Language Models for Embedded Sensing . In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking (ACM MobiCom ’24). Association for Computing Machinery, New York, NY, USA, 2236–2238. https://doi.org/10.1145/3636534.3695901